Node.js cluster module. You probably don't need it

P
Software Engineer.
Focused on Node.js and JavaScript.
Here to share my learnings and to learn something new.
Search for a command to run...
Software Engineer.
Focused on Node.js and JavaScript.
Here to share my learnings and to learn something new.
OTTIENI CERTIFICATI IELTS/TOEFL REALI E AUTENTICI, CERTIFICATI GRE/GMAT, CERTIFICATI OET/PTE
WHATSAPP: +44 7537 185707 WHATSAPP: +44 7537 185707
CERTIFICATO IELTS
CETIFICATO TOEIC
CERTIFICATO Toelf
CERTIFICATO TCF
CERTIFICATO ESOL
CERTIFICATO GMAT
GRE. CERTIFICATO
CERTIFICATO CELTA/DELTA
OET. CERTIFICATO
ASSISTENZA INFERMIERISTICA. CERTIFICATO (RPN, RN)
Contattaci sul nostro sito web al link sottostante
WHATSAPP:+44 7537 185707 WHATSAPP: +44 7537 185707 Acquista certificato registrato, IELTS,TOEIC, Toelf,TCF,ESOL,GMAT,CELTA/
OTTIENI CERTIFICATI IELTS/TOEFL REALI E AUTENTICI, CERTIFICATI GRE/GMAT, CERTIFICATI OET/PTE
WHATSAPP: +44 7537 185707 WHATSAPP: +44 7537 185707
CERTIFICATO IELTS
CETIFICATO TOEIC
CERTIFICATO Toelf
CERTIFICATO TCF
CERTIFICATO ESOL
CERTIFICATO GMAT
GRE. CERTIFICATO
CERTIFICATO CELTA/DELTA
OET. CERTIFICATO
ASSISTENZA INFERMIERISTICA. CERTIFICATO (RPN, RN)
Contattaci sul nostro sito web al link sottostante
WHATSAPP:+44 7537 185707 WHATSAPP: +44 7537 185707 Acquista certificato registrato, IELTS,TOEIC, Toelf,TCF,ESOL,GMAT,CELTA/
Appreciate it
In Node.js, there are 4 primary types of streams: readable, writable, transform, and duplex. In the previous article, we looked at the readable streams in detail. Perhaps you've heard something about writable streams or even used them. But there is a...

In Node.js we have different types of streams, and one of them is the Readable stream. You may have heard of it, or perhaps even used it a few times. But do you know how to use it effectively? This question of efficiency comes when we're dealing with...

Have you ever worked with Node.js streams? What was your experience like? When I first tried to work with streams, I was confused, to say the least. The concept was completely new to me. I thought I could just ignore them, but it turns out they're ev...

Profiling your Node.js applications could be exhausting, especially when you have to switch between different tools to get a full picture of your app's performance. The constant switching of contexts can kill your productivity. What if I tell you tha...

In the previous article, we talked about Atomics in Node.js and the problems they solve in multithreaded programs. While Atomics API is powerful, it is not always convenient to work with it simply because it is just too low level. Other programming l...

When you start learning more about the Node, you might encounter a thing called cluster module.
You may initially be confused about the difference between simply spawning processes and using clusters to do so — at least I was.
But there is a difference, and it is significant. Actually, it is so significant that you don't need to use the cluster module in most of the cases.
In this article we'll look into more details about the cluster model. What is it, how it works, and answer the main question: "Why are you probably good without using it?"
First, let's understand a cluster and the difference between it and simply spawning new processes manually.
A cluster is simply an abstraction over a group of processes that is glued with some network features.
A cluster consists of four main components:
The main process
Worker processes
Inter-process communication (IPC)
Load-balancing mechanism
You can see that the cluster is, by default, provided with a load-balancing mechanism, unlike a group of manually created processes.
There is also a slight distinction in how the process created by cluster is different from the one created manually. Here is what the documentation says about it
server.listen({fd: 7})Because the message is passed to the primary, file descriptor 7 in the parent will be listened on, and the handle passed to the worker, rather than listening to the worker's idea of what the number 7 file descriptor references.
server.listen(handle)Listening on handles explicitly will cause the worker to use the supplied handle, rather than talk to the primary process.
server.listen(0)Normally, this will cause servers to listen on a random port. However, in a cluster, each worker will receive the same "random" port each time they dolisten(0). In essence, the port is random the first time, but predictable thereafter. To listen on a unique port, generate a port number based on the cluster worker ID.
Now, let's explore the cluster components in more detail.
The main process is responsible for creating a cluster. It creates child processes called worker processes or simply “workers.”
The main process doesn’t directly process any of the requests coming to the server. It's responsibility to manage the cluster and distribute incoming requests between worker processes.
Worker processes are the workhorses. They are responsible for processing requests and giving responses to the clients.
IPC is the glue of clustering. It enables processes to exchange information, such as their health status and different data, and handle errors properly.
For example, we can spin up a new worker process in case some of them are crushed because we have information about the crush. That way, the cluster can always maintain the required number of workers.
Load-balancing, built into the cluster, prevents overloading a single worker. Cluster can employ two main load-balancing strategies, which we will see later in this article.
We’re ready to dive into the details of how the cluster components work together.
To better understand the concept, we’ll create a simple server using the cluster module.
import { fork, isPrimary } from 'node:cluster';
import { createServer } from 'node:http';
import { availableParallelism } from 'node:os';
if (isPrimary) {
const numbuerOfCPUs = availableParallelism();
for (let i = 0; i < numbuerOfCPUs; i++) {
fork();
}
} else {
createServer().listen(8000);
}
Let’s break it down. We start by checking whether the current process is the main one (primary). We use the same file to start both the main process and all of the worker processes, so we have to check what kind of process we’re in before going any further.
Here is how the initial state of the application looks like:

Here is the picture after creating the worker processes:
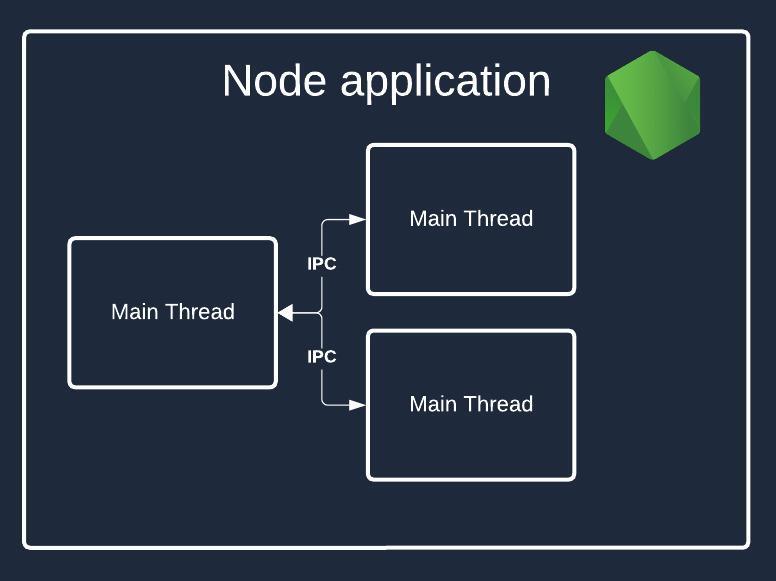
In case a process is main, we check how many CPUs are available using the availableParallelism function. It is a tiny wrapper around the libuv library function with the same name. We’re doing so to utilize the maximum resources available at the moment for cluster creation. It might not be ideal for all use cases, and you have to play with it to see what number best suits your needs.
As a simple example, where the number returned from availableParallelism might not be the best for you is having continuous running processes for external jobs like sync with external services and others. We have to take those processes into account while creating a cluster so both of them, cluster workers and other running processes, can be as efficient as possible.
Lastly, in the else block, we write code that all worker processes will run. In this case, it is creating an HTTP server on the 8000 port.
Notice that while we’re passing the same exact port for each of the workers that we create, it doesn’t mean that every worker will run on the 8000 port. Only the main process establishes a connection.
How the server handles incoming requests heavily depends on the load-balancing strategies in a cluster. The cluster employs two main load-balancing strategies: round-robin and shared handle.
There are three main factors that dictate which type of load balancing will be used:
Server configuration. The cluster can be configured via the NODE_CLUSTER_SCHED_POLICY environment variable, which takes two values: rr and none.
Operating system. On Windows, Node.js uses the shared handle by default because round-robin doesn’t perform well due to OS-specific constraints.
Connection type. A shared handle is used for UDP connections. The reason is simple: UDP is connectionless, and round-robin works only with TCP connections, like HTTP.
Round-robin (default) strategy. The round-robin strategy is used by default. This type of load-balancing relies on the round-robin algorithm to distribute incoming requests between worker processes. The main process plays the manager’s role and runs the algorithm to make it possible. The following picture shows how it works:

Shared connection (handle). The second type of load balancing is a shared handle. The main process establishes a connection with a port and creates the handle, which is simply a reference to the port where the connection is established. After that, the main process shares this handle with all of the worker processes. All of this happens during a cluster initialization process.
The difference with shared handles is that the main process no longer acts as a manager. It doesn’t distribute the incoming requests by itself; instead, the underlying OS mechanism fulfills this role:
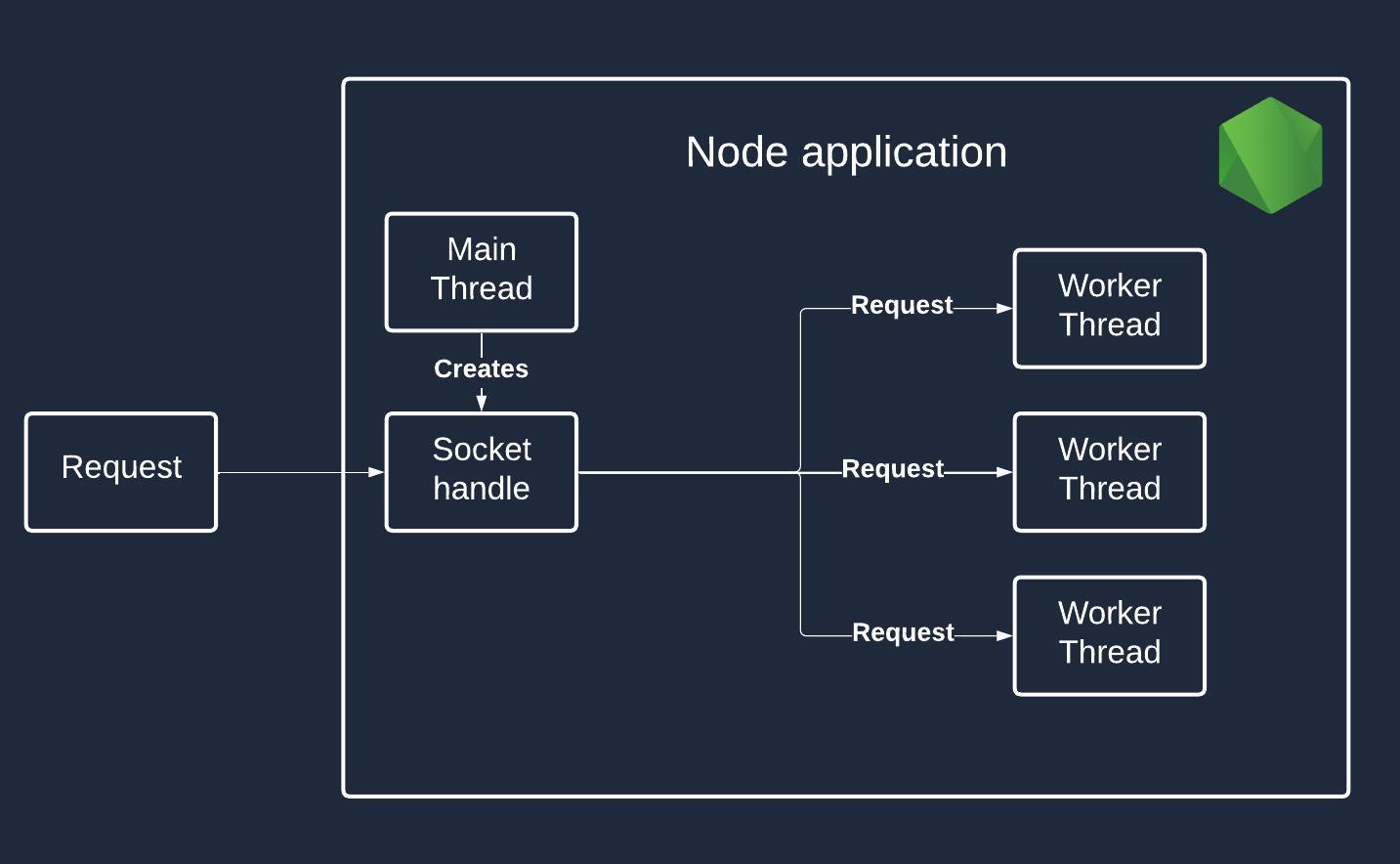
In both cases, the worker process is responsible for fulfilling the requests and sending back the response.
One of the main topics when it comes to scalability is the difference between using the clustering module and traditional pipelines (the process of building and delivering your applications to the final users) like Docker, Kubernetes, Nginx, and others.
When we talk about scaling via cluster, we always refer to a single server. We’re trying to scale our application within one server only by using multiple processes. This approach is prone to failure if the whole server experiences troubles.
Using traditional pipelines, we’re not limited to a single server. In fact, we can employ as many servers as we need to keep our application up and running.
Node.js developers usually manage clusters themselves. They monitor the server load, balance it properly, and scale whenever needed.
On the other hand, we have separate engineering roles and teams that manage traditional pipelines. This field is huge, and it is beneficial to have specialized people who apply the best tools and practices to ensure the best delivery and responsiveness of applications.
Using cluster only, we're very limited in options for load-balancing strategies, deployment strategies, and reactions to failures. Sure, we can write something custom, like a custom load-balancing strategy, but do you really want to spend time on it?
On the other hand, traditional pipelines already provide everything you might need in terms of load-balancing, deployment, and others. You just have more options, and those options are objectively better, and you don't have to write anything from scratch.
The cluster module was meant to solve a wide range of tasks, such as scaling, making applications more resilient, performing tasks in an isolated environment without blocking the main thread, and load-balancing incoming requests.
At the same time, external tooling can solve most of those problems when it comes to scaling. We’re left with a single reason to use the module — we want to ensure the isolation of running tasks inside different processes.
But you can do it manually by spawning different processes.
The only case where I see the module is useful is if your team is small and you don’t have the time and resources to invest in building a full pipeline with all the tooling for load-balancing, deploying, and scaling.
Overall, if you have extra time or people who can configure the pipeline, I strongly recommend doing so instead of relying on cluster to scale your application.