Introduction to Reactive Programming

Software Engineer.
Focused on Node.js and JavaScript.
Here to share my learnings and to learn something new.
You've probably heard something about reactive programming before, but do you know what it means? It is one of the topics that bring more confusion than clarity when you try to google it. There are a lot of examples out there, but most of them have a hard time conveying the core idea clearly and simply without any references to a particular framework, library, or platform. We'll explore what it is and how it works. Stay tuned!
Common misconceptions
Before diving into the topic, let's briefly review what reactive programming is not and the difference between it and the topics that it is usually confused with.
Reactive system
The first on the list is the reactive system. The main idea behind the reactive system is architecture. It is a high-level abstraction that enables us to build reliable distributed systems. This concept even has its reactive manifesto where key concepts of such systems are highlighted. If you are interested in this topic Amazon has an extended list of reactive manifesto and it is a good starting point.
Event-driven programming
The two programming paradigms enable us to work with asynchronous logic. Although event-driven programming shares some similarities with reactive programming, they have conceptually different ideas behind them. The main idea of event-driven programming is events and their handlers while reactive programming focuses on asynchronous data streams. We’ll discover more details and differences between these two in upcoming articles.
Exploring reactive programming
Now, when we know what it isn’t we can talk about what it is. The main building block of reactive programming is asynchronous data stream and it is all about their interconnections. To make it easier to understand let’s break it down with a help of an example.
Excel sheet
As an example, we will use an Excel sheet and a very simple formula to demonstrate how things work. Imagine that we have a formula for calculating net profit from some sale after taxes. It might look like this.

You can see that formula is pretty simple (for those curious of you the actual formula looks like this: "sell price x (1 - taxes rate)" where 1 is 100% and "taxes rate" is a decimal value). Let's fill it with some values.
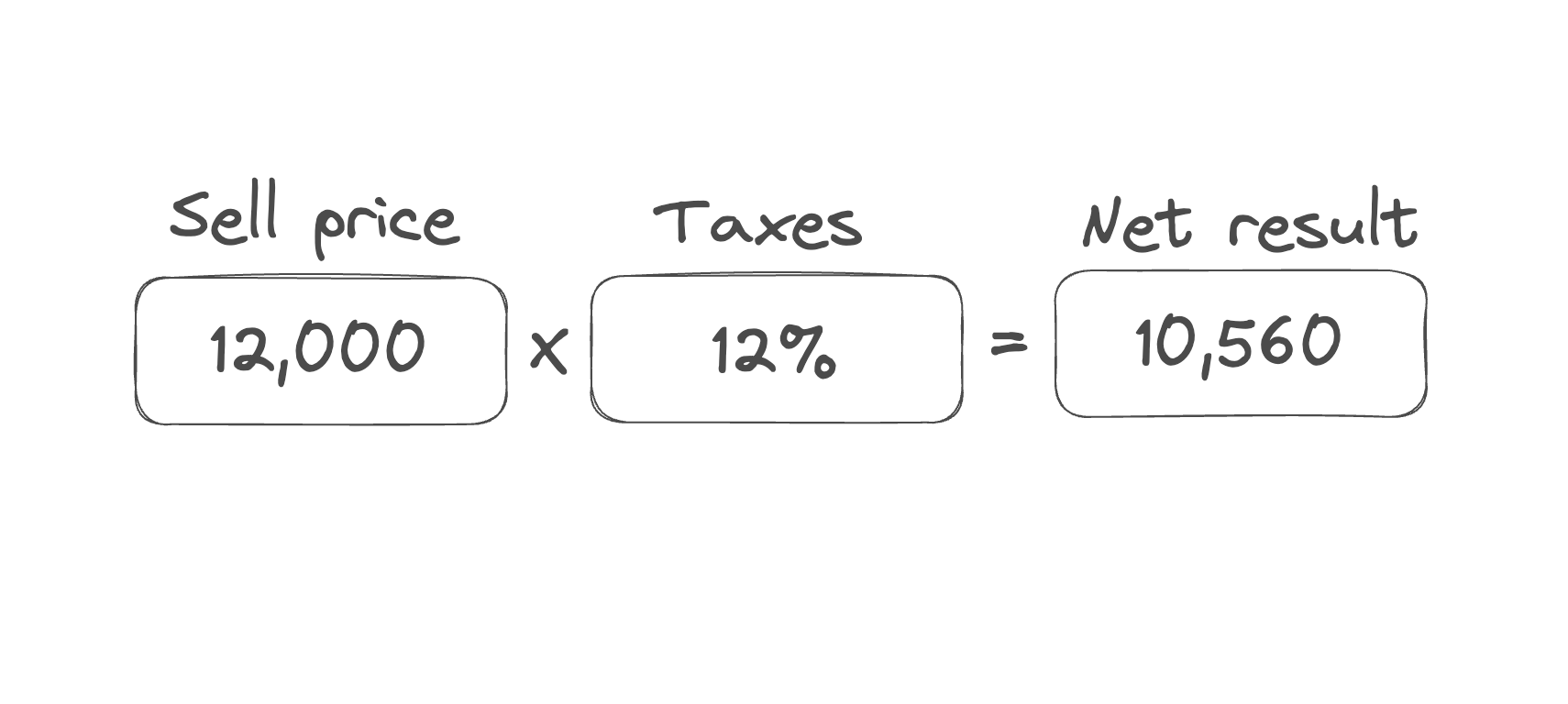
We can already spot the asynchronous data stream here! Well, there are at least 3 of them: the "Sell price" cell value, the "Taxes" cell value and the "Net result" cell value. The "Net result" cell value is calculated by taking the values of the other 2 cells and performing calculations based on the formula.
So far, so good. But why are they called async data streams, and what does it even mean? You can see a data stream as a value over time. If we compare it to a simple variable, the variable would represent a value at a specific point in time (whenever we decide to read its value).
The asynchronous part comes from the way we work with these data streams. We are "asking" the value itself to tell us whenever it changes. For those familiar with JavaScript it might sound somewhat similar to promises - and it is! Different patterns describe such behavior which we will dive into later.
Back to our example. The next step is to change the "Sell price" cell value and see what is going to happen.
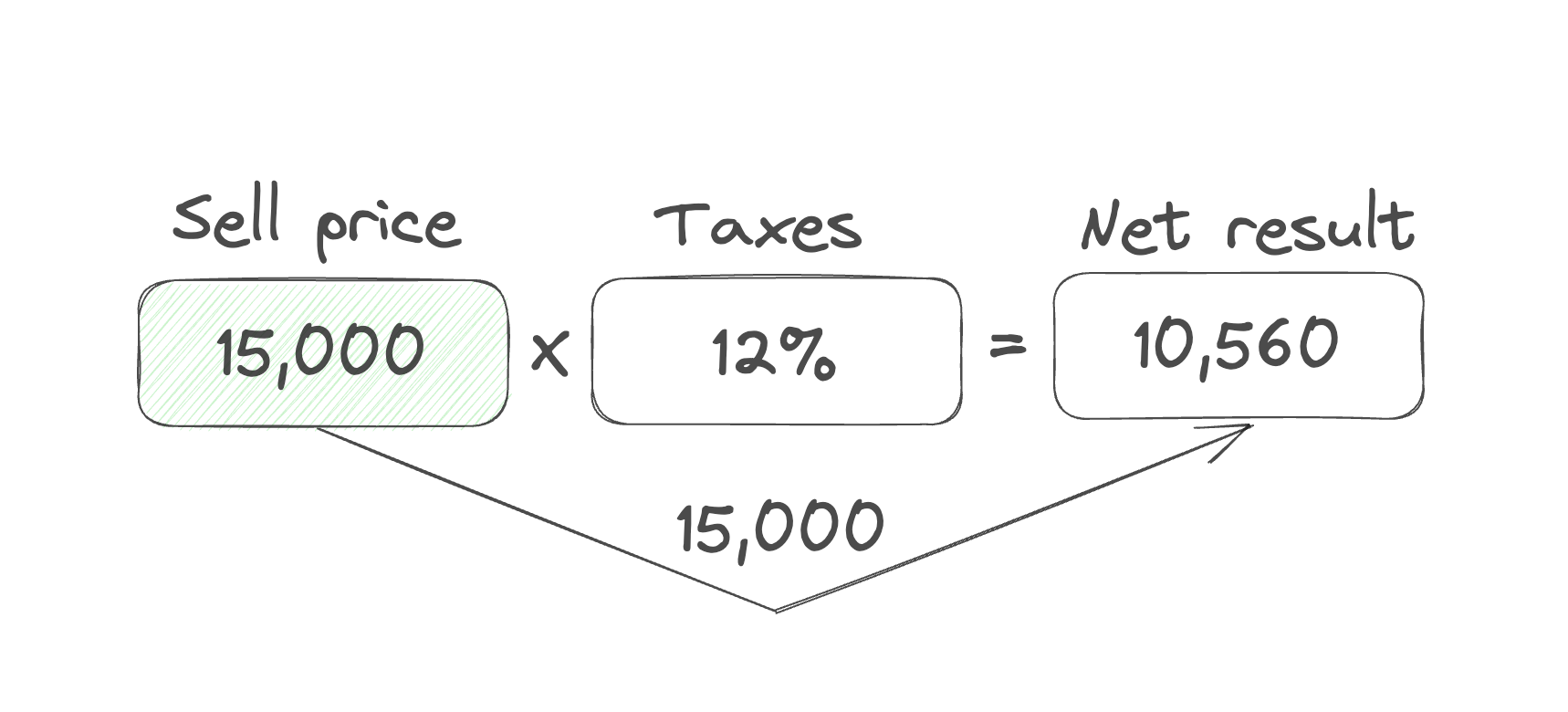
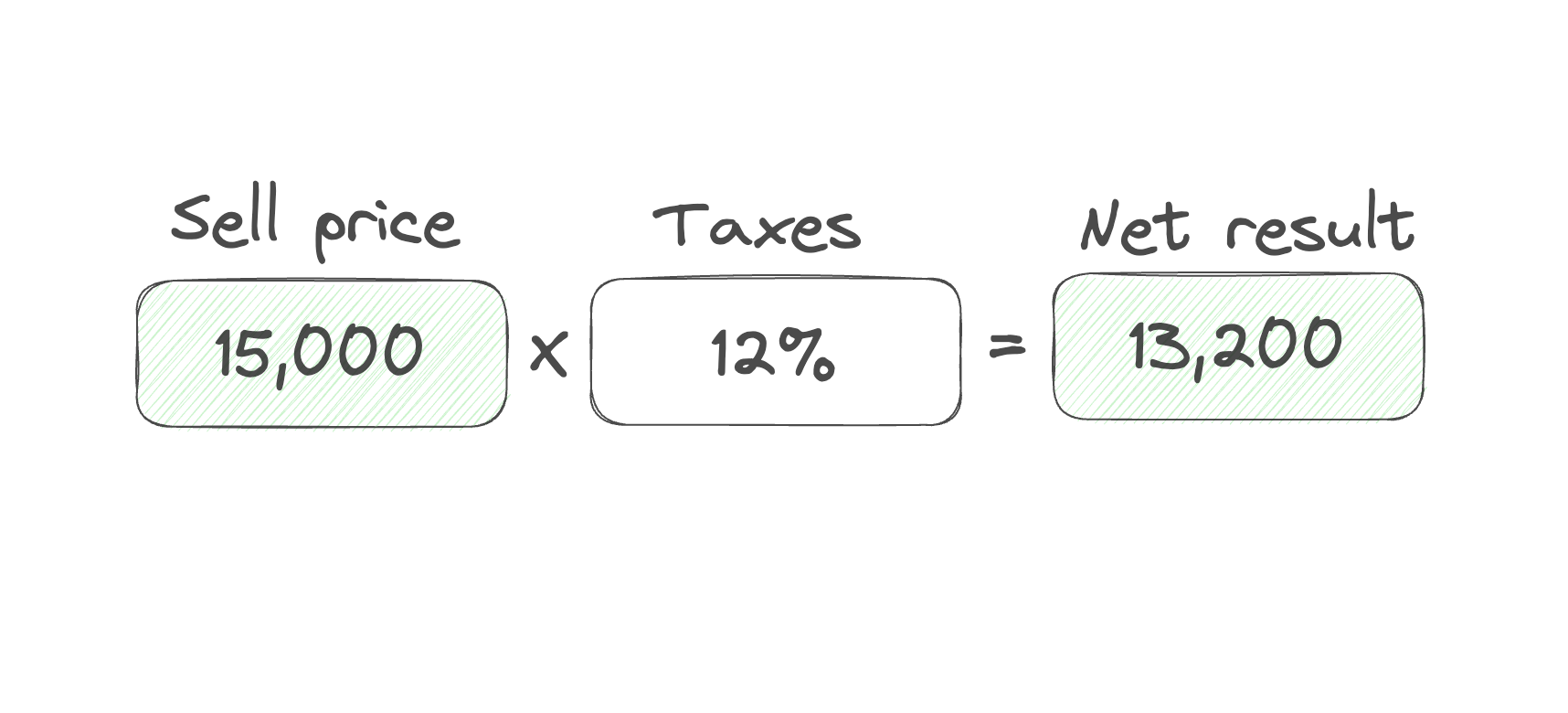
It is not only changing its value but informing everyone interested, in this case, the "Net result" cell. After receiving a new value from the "Sell price" cell it recalculates its value.
Benefits
There are strong reasons why this approach gaining traction. Here are a few:
Code becomes more granular and less coupled. We can write specific logic related to the "Net result" cell from the example only where it belongs. There is no need to keep logic for all cells in one place.
Switch from imperative to declarative code. In short, the declarative style allows us to write less verbose code that focuses on the result rather than the path to it.
Conclusion
Reactive programming is the paradigm that focuses on asynchronous data streams. Those data streams can be perceived as a value over time compared to simple variables that stand for value at a certain point in time. Such data streams inform interested consumers about new values allowing them to execute specific logic based on it. The paradigm has great benefits in terms of granular and less coupled code as well as imperative style.




