The Ultimate Guide to Cron Jobs in Node.js

P
Software Engineer.
Focused on Node.js and JavaScript.
Here to share my learnings and to learn something new.
Search for a command to run...
Software Engineer.
Focused on Node.js and JavaScript.
Here to share my learnings and to learn something new.
No comments yet. Be the first to comment.
In Node.js, there are 4 primary types of streams: readable, writable, transform, and duplex. In the previous article, we looked at the readable streams in detail. Perhaps you've heard something about writable streams or even used them. But there is a...

In Node.js we have different types of streams, and one of them is the Readable stream. You may have heard of it, or perhaps even used it a few times. But do you know how to use it effectively? This question of efficiency comes when we're dealing with...

Have you ever worked with Node.js streams? What was your experience like? When I first tried to work with streams, I was confused, to say the least. The concept was completely new to me. I thought I could just ignore them, but it turns out they're ev...

Profiling your Node.js applications could be exhausting, especially when you have to switch between different tools to get a full picture of your app's performance. The constant switching of contexts can kill your productivity. What if I tell you tha...

In the previous article, we talked about Atomics in Node.js and the problems they solve in multithreaded programs. While Atomics API is powerful, it is not always convenient to work with it simply because it is just too low level. Other programming l...

One of the most common features of each application is task scheduling. For example, an application needs to send email reports about some operations once every 8 hours to a certain number of users.
While it is a common task, people in the Node.js community still get confused about how to implement it, what options we have to create and manage those tasks, and the pros and cons of each option.
In this article, we’ll answer all those questions, giving you a clear picture of the tools you have at your disposal.
The world of task scheduling uses different terms that basically mean the same thing: jobs or tasks that the application performs on a schedule.
Many people call those cron jobs. However, this term can cause more confusion, especially if you’re just starting your journey on the backend.
For example, cron is a UNIX-based scheduler. What does it have to do with your application if you're running it on a Windows server?
A better term for it would be “scheduled tasks.” The name itself is crystal clear; you don’t have to second-guess what it stands for.
This term will be used throughout the rest of the article.
Before exploring the different tools and approaches, it's important to understand your application's specific requirements. Considering the following factors will help you to make an informed decision.
Application and infrastructure scale
High-frequency tasks
Long-running tasks
Task stacking
Let's explore each of these factors in more detail.
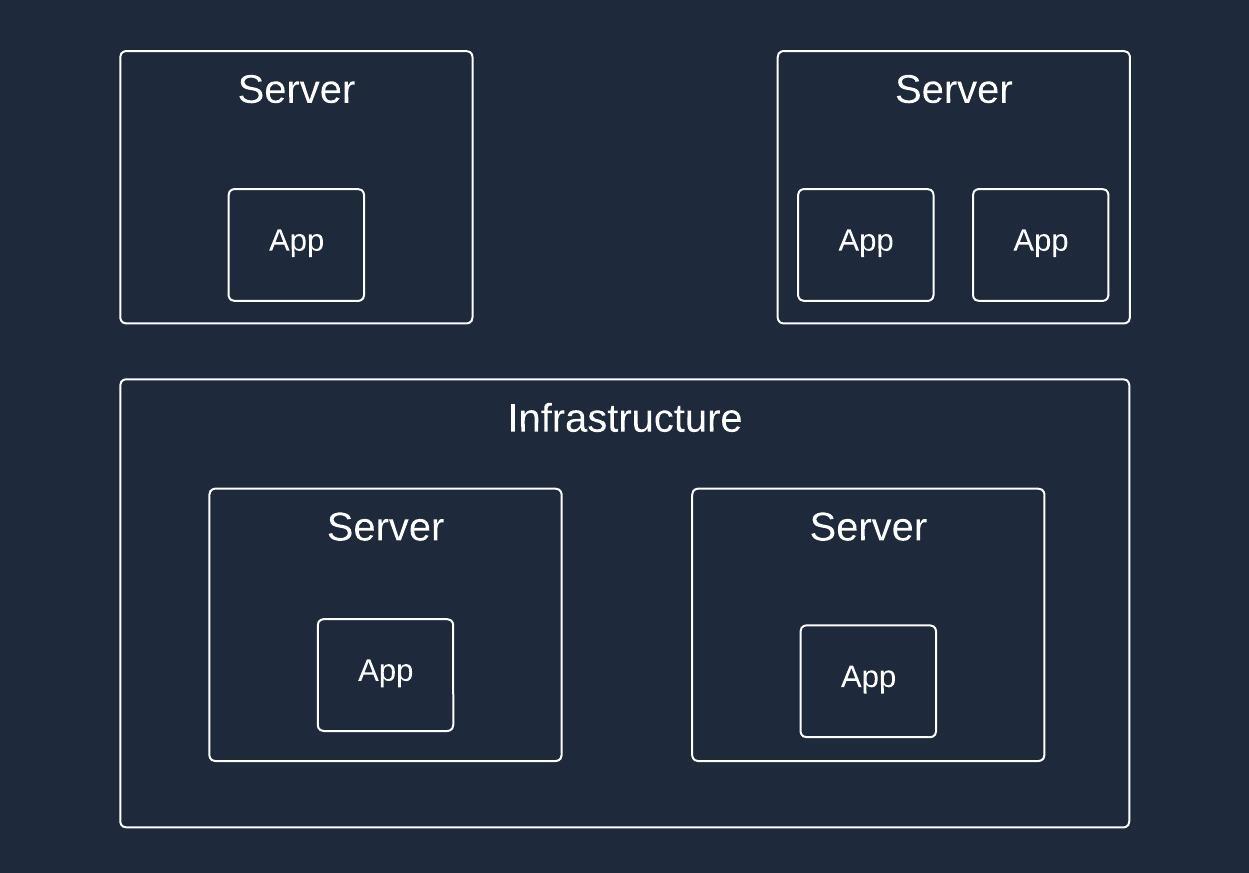
You have to understand the scale of your application and underlying infrastructure. It’ll allow you to make a reasonable decision on what approach to choose.
To name a few cases:
A single instance of application is running on a single server
Multiple instances of application are running on a single server
Multiple instances of applications are running on multiple servers
It is not limited only to those 3. You might have a different setup and infrastructure configuration. The point is that you have to understand it before deciding on the task scheduling approach.
If you need to run tasks at intervals shorter than 1 minute, your options will be more limited. Some scheduling solutions don't support high-frequency tasks out of the box at all or require additional workarounds.
Consider the minimum interval between tasks that your application requires, and ensure that the chosen solution fits those needs.

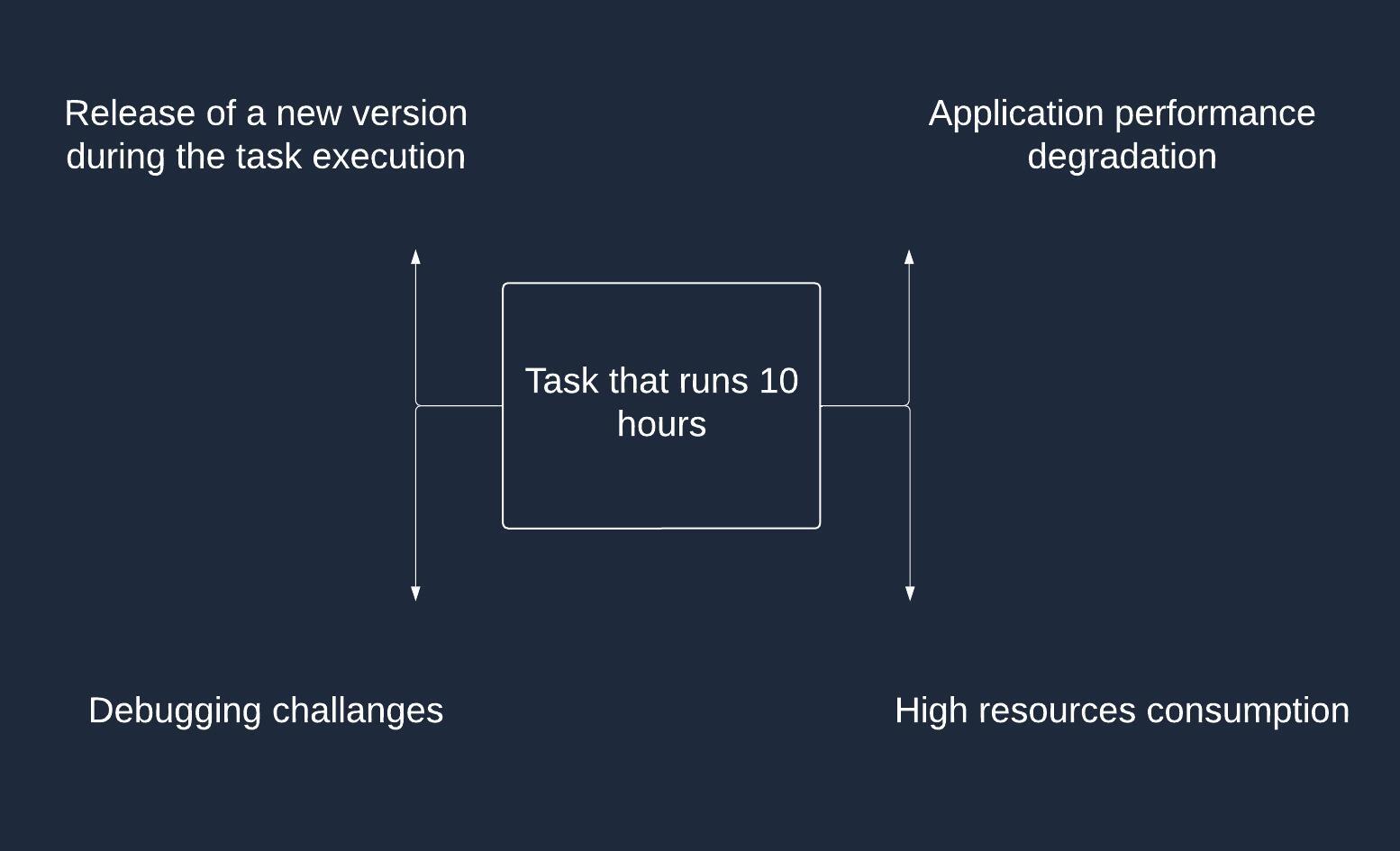
Long-running tasks introduce their own set of challenges. These tasks can exacerbate issues like memory leaks, which may not be apparent in applications without long-running processes. When implementing long-running tasks, consider the following challenges:
Debugging complexity: Long-running tasks can be harder to debug due to their extended runtime and potential interactions with other parts of the system.
Maintenance and updates: Careful planning is required when performing maintenance or updates on applications with long-running tasks to ensure minimal disruption and proper handling of in-progress tasks.
Resource management: Long-running tasks consume system resources over an extended period. Proper resource management, such as memory and CPU usage, is crucial to avoid performance degradation and memory leaks.
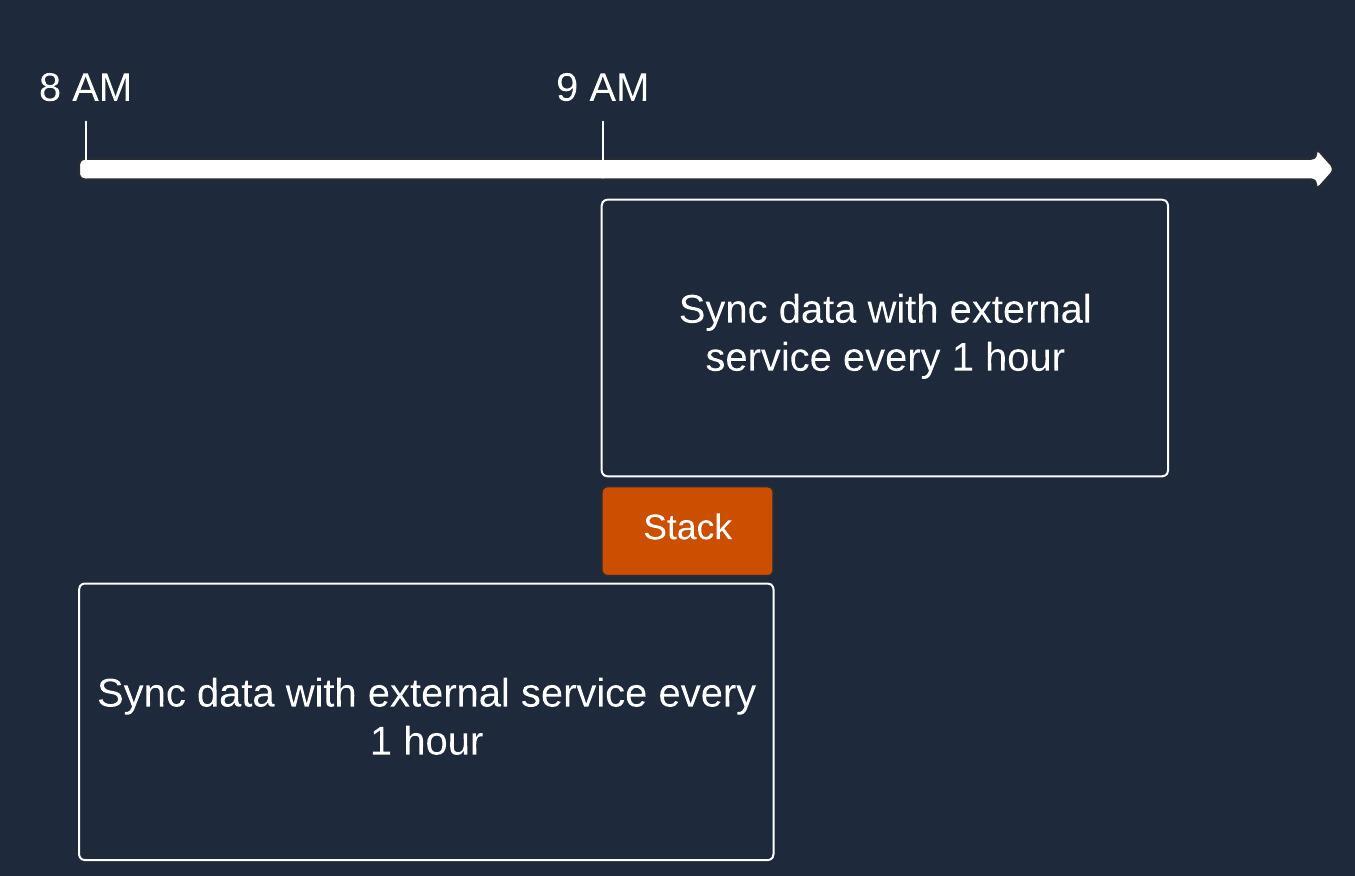
Task stacking occurs when a new task is started before the previous one has been completed. This can happen when the scheduled interval is shorter than the task's execution time.
Task stacking can lead to resource contention, performance degradation, and unexpected behavior. When selecting a scheduling solution, consider how it handles task stacking and whether it provides mechanisms to prevent or manage such situations.
While all scheduled tasks share the common characteristics of having a specified execution time and associated code, they differ in how and where they are scheduled and managed. In this section, we'll explore the various approaches to scheduling and managing tasks, including:
UNIX-based scheduling with cron
Runtime scheduling
Runtime scheduling with persistence
Cloud-based scheduling solutions
Each approach has its own pros and cons, which we'll discuss in detail.
Cron is a long-standing and widely-used scheduler in UNIX-based systems. It allows you to schedule tasks, known as "cron jobs," to run at specific intervals of time.
The interface through which you schedule tasks to cron is called crontab (cron table). Crontab uses a specific syntax to define the schedule.
Cron runs a cron daemon, a single process responsible for managing all the scheduled tasks. When a new task is scheduled, the daemon starts monitoring it with a frequency of 1 minute. When a task is due to run, cron creates a separate process for that task and executes it.
Pros:
Flexibility: Cron is a versatile tool for running various types of scripts and programs on a scheduled basis.
Process isolation: Each cron job runs in its own separate process, providing a level of isolation and minimizing the impact of one task on others.
Reliability: Cron has been around since 1975 and has proven to be a reliable and stable solution for task scheduling.
Cons:
Single machine limitation: By default, cron is limited to a single machine, which can make it harder to scale for larger workloads.
Task stacking: If a task takes longer to execute than its scheduled interval, multiple instances of the task may start running concurrently, leading to resource contention. Cron doesn't have built-in mechanisms to prevent this.
Limited fault tolerance: Cron doesn't provide built-in error handling functionality. If a task fails, cron won’t automatically retry it. You need to implement your own error handling and retry mechanisms.
Runtime scheduling refers to scheduling tasks directly within the application code. This approach is facilitated by various ready-to-use libraries in the Node.js ecosystem, such as node-cron, corn, croner, and others. While these libraries may have different implementation details, they all operate on the same fundamental principle.
Under the hood, these libraries typically use setTimeout or setInterval functions to schedule tasks. When your application starts, the scheduled jobs are initialized and set to run at their specified intervals.
Pros:
Simplicity: Runtime scheduling is easy to set up and get running, as it doesn't require any additional infrastructure or external dependencies.
Quick development: For simple use cases or prototypes, runtime scheduling allows you to implement task scheduling quickly without the overhead of more complex solutions.
Cons:
Resource contention: Not all solutions execute tasks in a separate process/thread. This means that if you run CPU-intensive logic inside a task, you have to be aware of particular implementation details to ensure that those tasks won’t block the main thread.
Deployment challenges: When deploying a new version of the application, all scheduled tasks will be rescheduled because all timers run inside of the same process as the application code (unless you separate it into a dedicated, independent process). It results in delayed task execution.
Scalability limitations: As the application scales beyond a single instance, managing runtime-scheduled tasks becomes increasingly difficult. Each application instance runs the same code and schedules the same tasks, leading to duplication and conflicts.
Task stacking: If a scheduled task takes longer to execute than its specified interval, multiple instances of the task may start running concurrently. This can result in resource contention and unexpected behavior, especially for long-running tasks.
Runtime scheduling can be a good fit for simple applications or prototypes where you want to test and visualize scheduled jobs quickly. However, it may not be the most suitable approach for production-grade applications that require scalability, reliability, and efficient resource utilization.
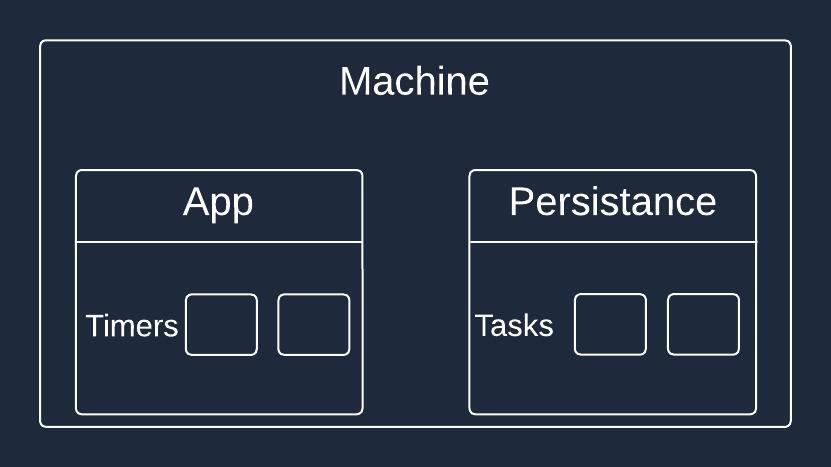
In this case, both task data and timers reside within the application.
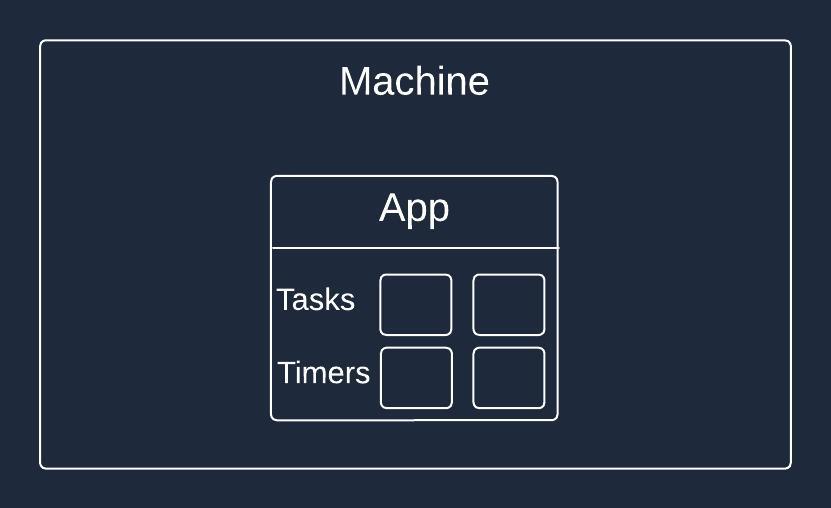
Runtime scheduling with persistence builds upon the basic runtime scheduling approach and introduces a persistence mechanism to store and manage scheduled tasks.
By incorporating a persistence layer, the application can store information about scheduled tasks in a database or a persistent storage system. This allows the application to track and recover tasks even after a restart or a new deployment, ensuring that tasks are executed on time.
Two notable libraries in the Node.js ecosystem provide runtime scheduling with persistence: Bull (or BullMQ) and Agenda.
Bull is a popular library that uses Redis, an in-memory data store, as its persistence mechanism.
Agenda is another library that provides runtime scheduling with persistence using MongoDB. It's important to note that the Agenda may not be actively maintained, with the last major release dating back to November 2022 (as of May 2024).
Unlike Ageda, Bull is actively maintained. The downside of Bull is it uses in-memory databases. If your server goes down, all jobs are lost.
Pros:
Persistence: Runtime scheduling with persistence ensures that scheduled tasks are not lost during application restarts or deployments. The persistence mechanism allows you to recover and resume tasks from where they left off.
Scalability: Abstracting task management from the main application and storing tasks in a separate persistence layer makes it easier to scale the application in the future. Multiple application instances can share the same persistence layer and coordinate task execution.
No task stacking: When using Bull, the queue-based structure ensures that tasks are executed in a reliable and orderly manner. New tasks are only started after the previous ones are completed, preventing all problems related to task stacking.
Cons:
Complexity: Implementing runtime scheduling with persistence requires additional setup, configuration, and learning compared to basic runtime scheduling. You need to set up and manage the persistence layer (e.g., Redis or MongoDB) and integrate it with your application.
Dependency on external systems: Relying on external systems like Redis or MongoDB introduces additional points of failure. If the persistence layer experiences issues or downtime, it can affect the task scheduling workflow.
Runtime scheduling with persistence offers a more robust and reliable approach compared to basic runtime scheduling. It addresses the issue of losing scheduled tasks during restarts and deployments and provides better scalability options. However, it also introduces additional complexity and dependencies on external systems.
With this approach, we move task information to the persistence layer. The application is now only responsible for running timers and executing tasks themselves (in case we still run everything in a single application instance).
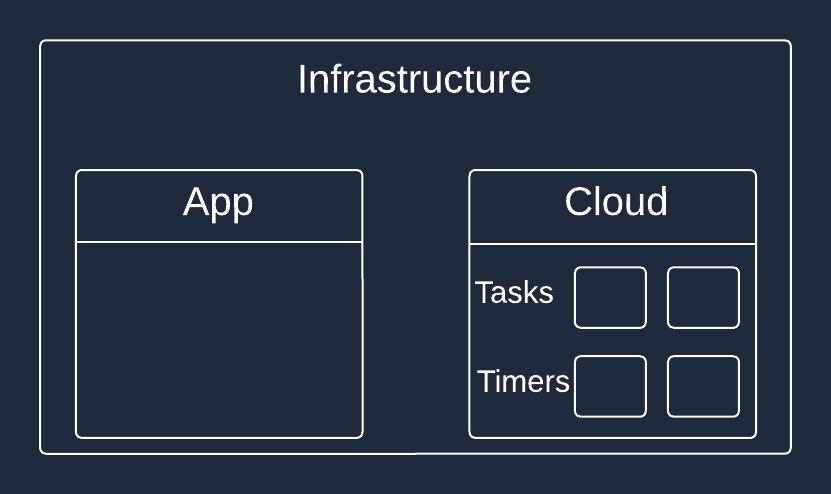
The other option is to move to the cloud. In this case, you don’t need to use any of the previous solutions to create, schedule, and persist tasks.
Popular cloud providers, such as Amazon Web Services (AWS) and Google Cloud Platform (GCP), offer dedicated services for scheduling tasks. For example, AWS provides the EventBridge Scheduler, while GCP offers the Cloud Scheduler.
Pros:
Decoupled architecture: Cloud-based scheduling solutions decouple the scheduling logic from your application code. This separation of concerns makes it easier to scale and maintain your application independently of the scheduling infrastructure.
Scalability and reliability: Cloud providers offer highly scalable and reliable scheduling services. They handle the underlying infrastructure, ensuring that tasks are executed on time and with high availability. You don't need to worry about managing the scheduling infrastructure yourself.
Flexibility and integration: Cloud-based scheduling solutions often provide flexible scheduling options, such as cron-based scheduling or more advanced scheduling patterns. They also integrate well with other cloud services, allowing you to build complex workflows and data pipelines.
Cons:
Learning curve: Cloud-based scheduling solutions require an understanding of a specific cloud platform and its services.
Cost considerations: While cloud-based scheduling solutions offer scalability and convenience, they come with associated costs. As your usage grows, the cost of using these services may increase. It's important to carefully evaluate the pricing models and estimate the long-term costs based on your application's needs.
Complexity in code sharing: If your application relies on code sharing between the main application and the scheduled tasks, using a cloud-based scheduling solution makes it increasingly harder to share the code. You may need to package and deploy your task code separately from your main application, which can require additional configuration and deployment processes.
In the world of Node.js task scheduling, there is no one-size-fits-all solution.
When deciding on a task scheduling approach for your application, it's critical to evaluate your specific needs and trade-offs carefully. Consider the scalability and reliability requirements, the complexity of setup and maintenance, and the potential costs involved.
Be open to exploring different options, adapting as your needs evolve, and finding the solution that best fits your application's goals and constraints.