Numeric Systems in JavaScript: From Fundamentals to Application

Software Engineer.
Focused on Node.js and JavaScript.
Here to share my learnings and to learn something new.
Have you ever stumbled upon cryptic codes like 0x2A or 0b101010 while working with JavaScript? These aren't typos or glitches but alternative ways to represent numeric values. In other words, those are different numeric systems.
Why bother with different numeric systems? Different numeric systems help us operate more effectively in areas like cryptography, 3D development, and binary manipulations.
This article dives into the details of these numeric systems, explaining their purpose, usage, and how they can be used in JavaScript.
Concept of an abstract number
Before discussing the details of each numeric system, let’s first focus on what numbers are and how we use them.
Imagine that you see three oranges.

If someone asks you, “How many oranges are there?” Your answer is obvious: three.
Imagine a different scenario. You’re living in Spain and can only speak Spanish. If someone asks you, “How many oranges are there?” in Spanish, you’ll answer: tres.
The abstract concept of 'the number of oranges' remains consistent across languages, as the meaning is the same in both English and Spanish. However, this abstraction is represented differently in each language.
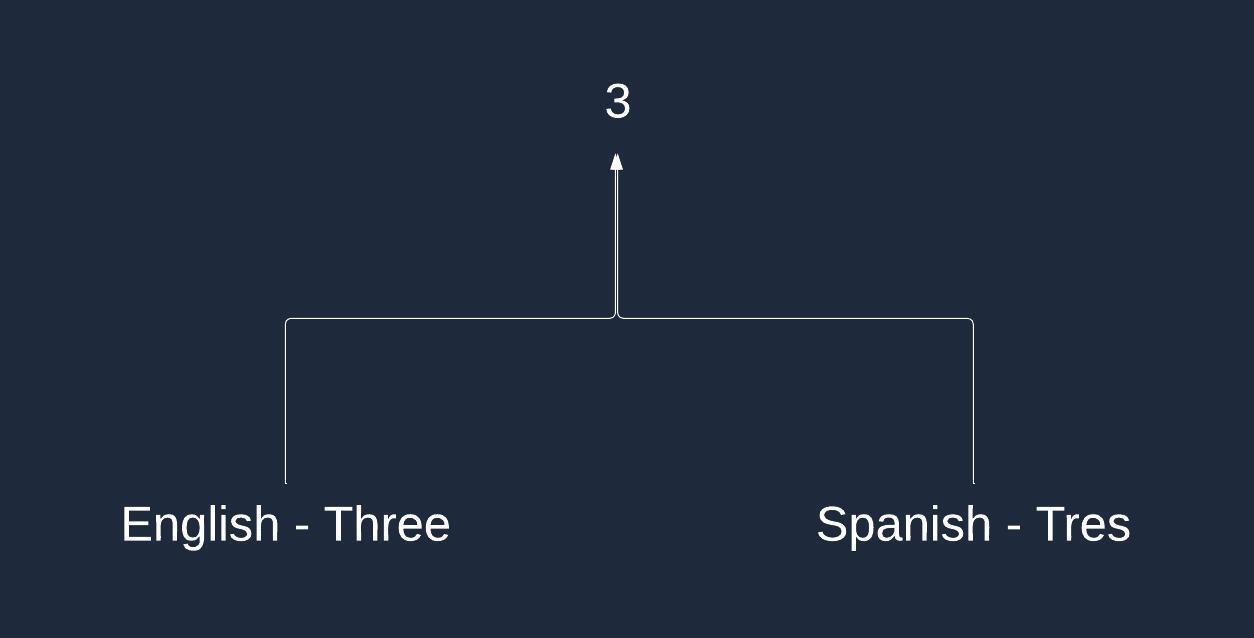
Different languages use different names for the same numbers. But at least we have the numbers that are common across all languages and always mean the exact same thing, right? Not really.
In addition to different languages, we have different numeric systems. A simple number 3 in a decimal system is represented differently in a binary system. In binary, it is 0011. Similar to English and Spanish, both 3 and 0011 represent the same abstract concept.
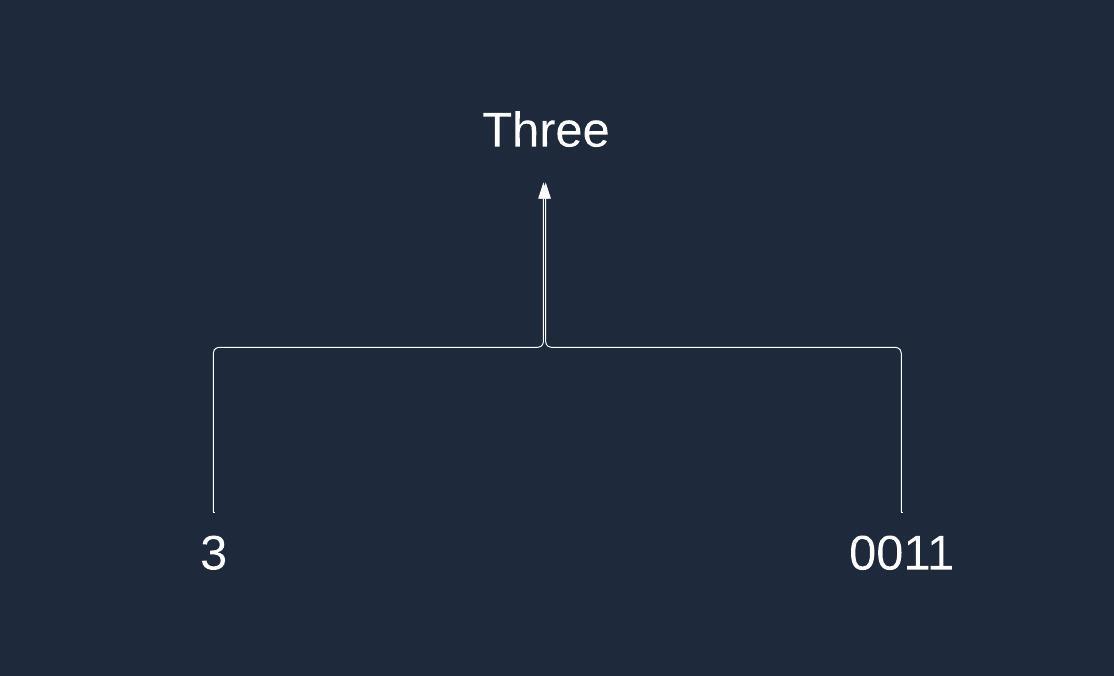
The reason people use different numeric systems is the same as why they use different words for the same number in different languages. Working and operating with them in certain cases is simply more convenient.
Notice that the previous two pictures don’t capture the essence of the abstract number behind them. A more appropriate representation of an abstract number would be something like this.
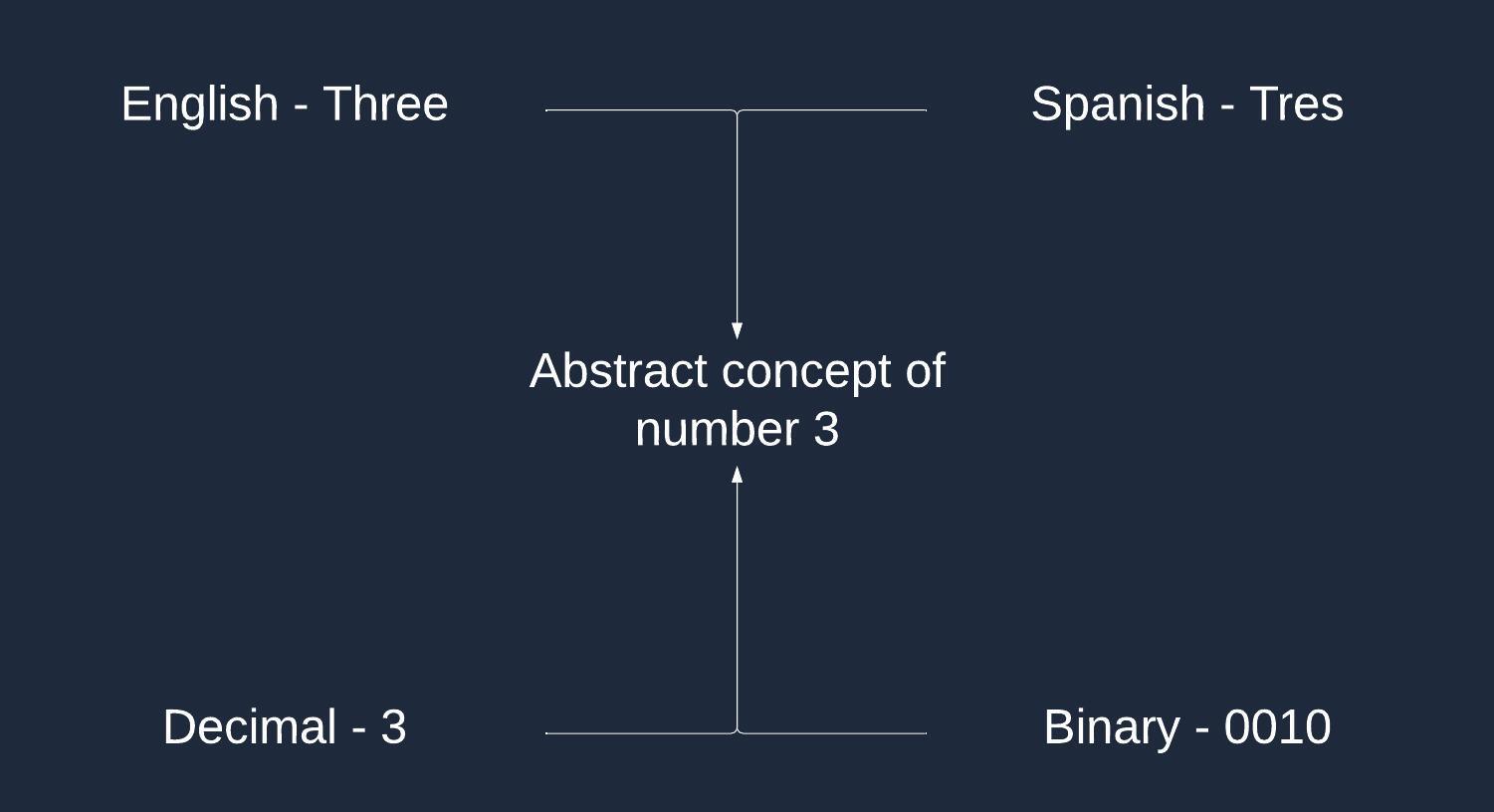
Numeric systems
Numeric systems are like different human languages. We use them in certain situations to understand and to be understood.
For example, at the lowest hardware level, computers talk in binary. Using decimals just won’t get you anywhere in the same way as using English to communicate with some Amazon forest tribe.
The good part? Numeric systems are not as complex as languages. It is quite easy to go from one numeric system to another, even using only pen and paper. With the power of a computer, you become a fluent speaker of different numeric systems.
There are a lot of different numeric systems, but the most popular are the following four:
Binary
Octal
Decimal
Hexadecimal
Likely, you won’t need to use any other numeric systems at all. That’s how popular these four systems are.
Notice, unlike human languages, which are usually tightly bound to a particular place where some group of people lives, numeric systems are all about the “base.” The base is basically how many numbers a particular system has.
For example, a binary system has a base of 2 because it uses only two numbers: 1 and 0. In decimal, we have 10 numbers starting from 0 to 9. The higher the base is, the more numbers there are.
Another interesting thing to mention is that a particular system doesn’t contain a number that is equal to or higher than the base of the system. In binary, we don’t have 2, and octal doesn’t include 9.
Next, we’ll look at each of the four numeric systems in more detail.
Binary system
The binary numeric system is the lingua Franka of computer hardware. It uses only two numbers, 1s and 0s, and surprisingly, it is enough to do the job.
Here is an example of how you count to 5 in binary:
0 0 0 1 - one
0 0 1 0 - two
0 0 1 1 - three
0 1 0 0 - four
0 1 0 1 - five
You might notice the strange zeros that go before the actual number. They are called leading zeros. We use them just to make numbers more readable. Putting any number of zeros at the start of the number does not change the actual value.
Octal system
The octal system was used in the past for computers and programming languages like PDP-8. Although there are not many use cases for it at this point, that doesn’t mean there are none. For example, the Unix file permissions mechanism is based on the octal numeric system.
Here is how you count from 6 to 10 using the octal system:
6 - six
7 - seven
10 - eight
11 - nine
12 - ten
Unlike binary, where we go to 10 straight after 1, it happens after 7 in octal. Remember, a numeric system doesn’t contain a number equal to or higher than the system base. That’s why the octal system doesn’t include the number 8.
Decimal system
The decimal numeric system is the one we all use daily. It is the most used numeric system in human-to-human interaction. Unlike other popular numeric systems, it is the only one that wasn’t the product of human-to-computer interaction but emerged in human-to-human interaction.
It is not the only one of a kind. Before that, people were using systems like the Roman numeric system or the Sexagesimal (has 60 numbers) numeric system, which was used by the ancient Sumerians, and we’re still using it (remember how many seconds in a minute).
As the name suggests, it operates with ten numbers starting from 0 and up to 9.
Hexadecimal system
The hexadecimal numeric system (hex) is widely used in software engineering. Here are just a few examples of where you can encounter it:
CSS colors. One of the most popular color notation in CSS is the hex notation. As an example, FFFFFF represents the black color.
Memory addresses.
UUID.
MAC address.
And, of course, error codes.
The hex numeric system includes 16 digits from 0 to F. Here is how you count from 9 to 13 in hex:
9 - nine
A - ten
B - eleven
C - twelve
D - thirteen
Notice that every number from 0 to 15 has a dedicated digit, unlike decimal, where we write ten as 10 instead of A.
Working with different numeric systems in JavaScript
After getting familiar with the most popular numeric systems, the next question is, “How do we use them in JavaScript?”
JavaScript provides specific prefixes to make the interpreter understand what numeric system we want to use. Let’s look at how we can write the number 13 in different systems using JavaScript:
Binary: 0b1101
Octal: 0o15
Decimal: 13
Hexadecimal: 0xD
Notice that for all four numeric systems except decimal, we add a specific prefix starting from 0 and followed by the letter specific to that numeric system. Leading 0 tells the interpreter to treat the value as a number; otherwise, it treats the value as a variable.
If you want to work with different numeric systems, JavaScript supports up to 36 base numeric systems. Be aware that using any non-standard (not binary, octal, decimal, or hexadecimal) numeric system may limit any mathematical operations. The only way to perform math operations with other numeric systems is through conversion to decimal and back. One way to convert a 36-base number to decimal is to use the parseInt function.
parseInt(‘ZAE’, 36); // results to 45734
Here is an example of implementing a function to sum a number with a base of 36.
function base36ToDecimal(base36Number) {
return parseInt(base36Number, 36);
}
function decimalToBase36(decimalNumber) {
return decimalNumber.toString(36).toUpperCase(); // Ensure uppercase
}
function sumBase36(num1, num2) {
const decimalSum = base36ToDecimal(num1) + base36ToDecimal(num2);
return decimalToBase36(decimalSum);
}
Conclusion
Understanding different numeric systems is a valuable skill for any developer. It goes beyond how computers process numbers; it's about how we, as developers, can communicate and work with data more effectively.
Knowledge of different numeric systems is fundamental and opens a number of opportunities, such as handling specialized data formats, working with low-level programming, buffers, etc.
Next, we'll take a closer look at the building blocks of digital data—bits and bytes—and how you can directly manipulate them using JavaScript.




