Node.js Performance Hooks: Mastering the Mental Model

P
Software Engineer.
Focused on Node.js and JavaScript.
Here to share my learnings and to learn something new.
Search for a command to run...
Software Engineer.
Focused on Node.js and JavaScript.
Here to share my learnings and to learn something new.
ALPHA KEY, A LICENCED CRYPTO RECOVERY HACKER, IS A GREAT REFERENCE
I can't stand to say that I truly appreciate the work and effort you put into my case. After being conned by two different recovery hackers, I woke up to find that almost everything had been taken from me. If I were to recommend a legitimate recovery hacker on Earth, I would recommend ALPHA KEY RECOVERY; they are the best so far. For any kind of recovery concerns, get in touch with ALPHA KEY RECOVERY HACKER EXPERT right now. Contact info Email: Alphakey@consultant.com WhatsaApp :+15714122170 Signal:+18622823879 Telegram: Alpha Key Recovery Website : https://dev-alpha-key.pantheonsite.io/
In Node.js, there are 4 primary types of streams: readable, writable, transform, and duplex. In the previous article, we looked at the readable streams in detail. Perhaps you've heard something about writable streams or even used them. But there is a...

In Node.js we have different types of streams, and one of them is the Readable stream. You may have heard of it, or perhaps even used it a few times. But do you know how to use it effectively? This question of efficiency comes when we're dealing with...

Have you ever worked with Node.js streams? What was your experience like? When I first tried to work with streams, I was confused, to say the least. The concept was completely new to me. I thought I could just ignore them, but it turns out they're ev...

Profiling your Node.js applications could be exhausting, especially when you have to switch between different tools to get a full picture of your app's performance. The constant switching of contexts can kill your productivity. What if I tell you tha...

In the previous article, we talked about Atomics in Node.js and the problems they solve in multithreaded programs. While Atomics API is powerful, it is not always convenient to work with it simply because it is just too low level. Other programming l...

Node.js includes a built-in module called performance hooks for precise performance measurement. But why use it when you can simply log timestamps and calculate the difference between two dates?
At least because it is precise. The module uses a monotonic clock that allows you, as a user, to make performance measurements and be sure that they are not corrupted.
At first, I struggled to understand how it works. It is an abstraction, and as with any abstraction, you need to put in extra effort to understand it. Existing materials didn’t help much with it.
The key to understanding performance hooks lies in understanding its underlying mental model. This article will provide an overview of the module's core concepts and a detailed explanation of how they relate to each other. By the end, you'll know how the performance hooks work.
It’s important to understand the underlying mental model to use performance hooks well. This section will explain the basic concepts behind performance hooks. With this knowledge, you can use them more effectively.
Let's start by exploring the different types of clocks used in performance measurement. In this context, a "clock" is an abstract representation of how we perceive time.
The first type is the wall clock. The W3C specification defines it as follows:
The wall clock's unsafe current time is always as close as possible to a user's notion of time. Since a computer sometimes runs slow or fast or loses track of time, its wall clock sometimes needs to be adjusted, which means the unsafe current time can decrease, making it unreliable for performance measurement or recording the orders of events. The web platform shares a wall clock with [ECMA-262] time.
In essence, the wall clock aligns with a user's perception of time, including system time adjustments and time zones. However, it operates independently of any specific process or user. Even if a JavaScript program using the wall clock stops, it continues to run.
The second type is the monotonic clock. The documentation describes it as:
The monotonic clock's unsafe current time never decreases, so it can't be changed by system clock adjustments. The monotonic clock only exists within a single execution of the user agent, so it can't be used to compare events that might happen in different executions.
Unlike the wall clock, the monotonic clock doesn't adjust to a current user. It exists only within a specific context, such as a single execution of a Node.js process.
The performance hooks module uses the monotonic clock. Why?
Because measurement accuracy is important, a wall clock is prone to user-specific time changes, like system time adjustments, especially during performance measurements.
Additionally, the monotonic clock offers higher precision than the wall clock, making it ideal for performance measurement.
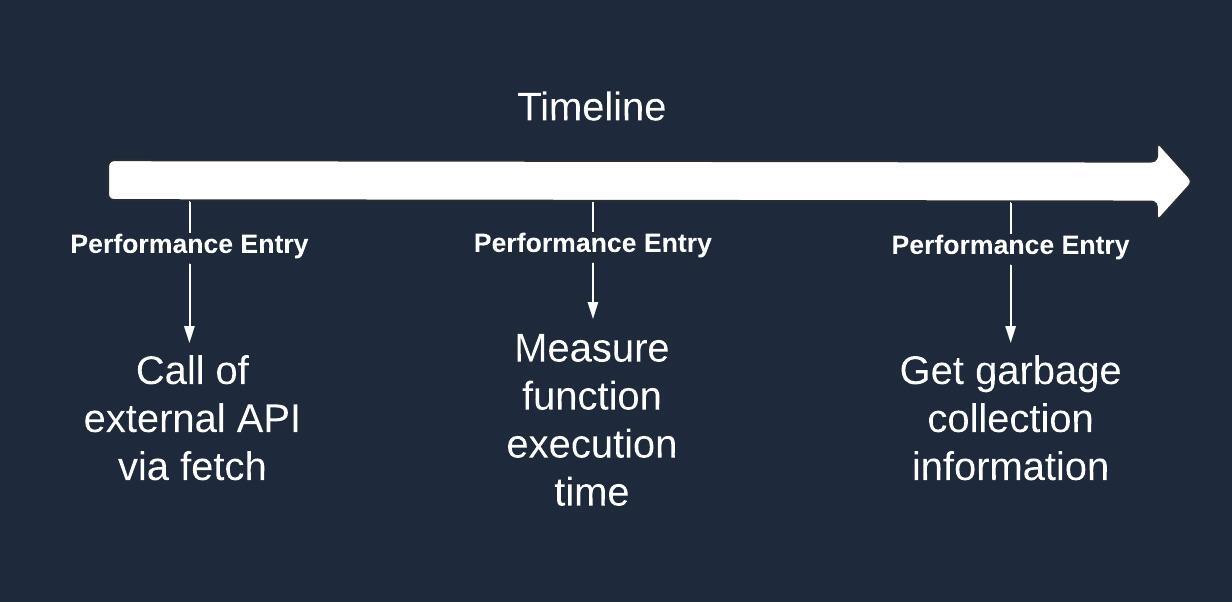
The concept of a Performance Timeline often confuses people due to a lack of clear explanations. Let’s end it right here and clarify some things about the topic.
In this context, a timeline is simply a sequence of events occurring over a specific period of time.
It's called a "performance timeline" because these events are specifically related to performance. These performance-related events are known as performance entries, which we'll discuss later.
The performance timeline concept is a mental abstraction. No code backs it up. Some events within the timeline can be buffered (stored temporarily) for later analysis. However, not all of them can be buffered. Therefore, those buffered events are not complete representations of the timeline but some part of it.
Performance entries represent the events that happen during program execution. Node.js provides the following types:
Mark
Measure
Resource
Node
The first three types (Mark, Measure, and Resource) are defined by the W3C specification, which Node.js aims to adhere to closely.
The fourth type, Node, is specific to Node.js. It's an abstract type that combines net, dns, gc, http, http2, and function.
The abstract Node types include many different performance entry types for the following two reasons:
They are all created only after some action is finished. For example, if a function finishes the execution or if we do a DNS lookup, the performance entry will be created only after the lookup is done.
They are only available inside of the Node.js, not in the browser.
The Mark and Measure types are also called user timings because the user decides when to create an entry. For example, you can create a Mark performance entry right in the function execution process, not strictly before or after.
The fetch function is the only one responsible for creating Resource entry types. This type is special because it is compatible with W3C specifications and can be used in web browsers, but it is not as flexible as user timings.
We’ve discussed the performance timeline and performance entries. The next logical step is to see the performance data. The measurements. That is where performance observer comes into play.
It enables you to collect and work with the performance entries that the program generates without much sweat.
To start using performance observer, you need first to configure it:
Create a performance observer and provide a callback function. The function is called whenever an entity you want to observe is created.
Call the observe method and provide configuration options as the function arguments.
import { PerformanceObserver, performance } from 'node:perf_hooks';
const obs = new PerformanceObserver(list => {
// Process the list of performance entries.
// The list contains the test performance mark entry.
});
// Configuration of the observe method
// where we want to monitor the mark entries
obs.observe({ entryTypes: ['mark'] });
// Callback of the performance observable is triggered
// because of the observe function configuration.
performance.mark('test');
Performance entries that you’re not interested in don’t trigger the performance observer callback.
import { PerformanceObserver, performance } from 'node:perf_hooks';
const obs = new PerformanceObserver(list => {
// Process the list of performance entries
});
// Observe function configuration
obs.observe({ entryTypes: ['function'] });
// The callback is not triggered because the entry type
// doesn’t match the observe function configuration
performance.mark('test');
Overall, this approach is a flexible way of observing different performance entry types.
The next important topic is when to start observing entries with the performance observer. From this point on, it gets deep, so be ready.
There are only two options: after and before creating a performance entry. I strongly recommend creating a performance entry after the call of the observe method.
The reason is simple: it makes code predictable.
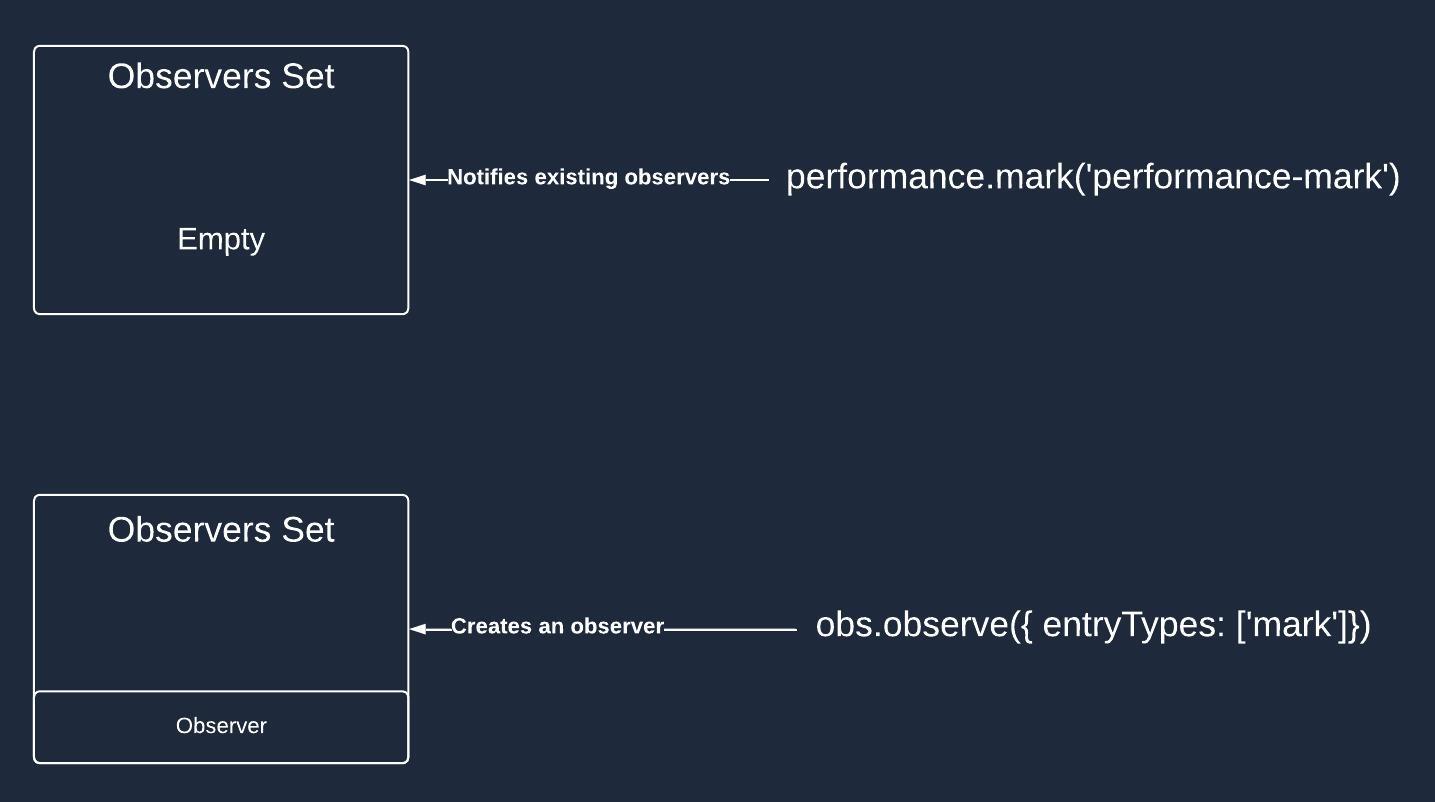
Consider the following example where we create a performance entry before calling the observe method:
import { PerformanceObserver, performance } from 'node:perf_hooks';
const obs = new PerformanceObserver(list => {
console.log(list);
});
performance.mark('performance-mark');
obs.observe({ entryTypes: ['mark'] });
The expected behavior is to see all related performance entries in the console. However, you still won't see anything in the console despite creating a matching performance entry type (the performance observer is configured for the Mark entry types, and we’ve created exactly one).
Why? Because of the specific way the performance hooks work. Let me explain.
The performance hooks manage several “global” (scoped inside of a file) variables, including the set of observers. The observer is added to this set not when we call the constructor of PerformanceObserver but when we call the observe method.
The observer’s callback is triggered whenever a new performance entry is created. In our case, performance.mark('performance-mark') creates the Mark performance entry and calls all existing observers interested in this type of performance entry.
In summary, the performance observer's callback wasn’t invoked simply because the observer didn’t exist when the performance entry was created.
Here is a picture to better illustrate the process:
Another important concept is buffers. Buffers enable you to get the historical sequence of performance entries that the program creates.
Don’t be afraid of the fancy word “buffer.” In reality, those are just arrays.
You should be aware of two types of buffers: local and global.
The local buffer is only related to the performance observer. This local buffer stores a sequence of events related to this particular observer. If the observer isn’t interested in some event types, they aren’t buffered.
Important note: those performance entries are buffered only for a period of time before creating a performance entry and calling the observer callback. After that, the buffer gets cleared. It allows us to see two events at the same in one callback call instead of having two separate ones:
const obs = new PerformanceObserver((list) => {
// The list contains two performance mark entries.
console.log(list);
});
obs.observe({ entryTypes: ['mark'] });
performance.mark('performance-mark-1');
performance.mark('performance-mark-2');
When it comes to global buffers, there are three of them:
Performance mark entries buffer.
Performance measure entries buffer.
Performance resource entries buffer.
Let’s look at the same example as with the local buffer but slightly modify it.
import { PerformanceObserver, performance } from 'node:perf_hooks';
performance.mark('performance-mark-1');
const obs = new PerformanceObserver((list) => {
// prints only performance mark #2
console.log(list);
// prints both performance marks because it works with global buffers
console.log(performance.getEntries());
});
obs.observe({ entryTypes: ['mark'] });
performance.mark('performance-mark-2');
You’ll see only one performance mark entry in the first console log because only one is called after the observer method invocation.
The performance.getEntries function gets data directly from the global buffers. It means we’ll see two performance entries in the second console log, even though one was created before the observer's creation.
After reading this article, you should have a solid understanding of the core concepts related to the performance hooks module such as:
Monotonic and wall clocks
Performance timeline
Performance entries
Performance observer
When to start observing the entries?
Performance hooks buffers
These concepts create a good foundation in terms of mental model and some API specifics.
Now, you shouldn’t have any problems using performance hooks and building your own abstractions upon them.