How to Profile Node.js Apps Using Chrome DevTools

Software Engineer.
Focused on Node.js and JavaScript.
Here to share my learnings and to learn something new.
I was confused when I heard you can use Chrome DevTools to profile Node.js applications. Why are we using browser tooling for Node.js applications? But it makes perfect sense, and it is one of the best options to do profiling.
Why? Because both Chrome and Node.js use V8, the DevTools are designed to work with V8, its memory heap, performance metrics, and more. From this perspective, it looks like a shiny start.
In this article, you’ll learn how to use DevTools to profile Node.js applications, focusing on three common problems during development: high CPU consumption, memory leaks, and unoptimized asynchronous operations.
Setup
To see profiling in action, we need some code. For this purpose, I created a GitHub repository with all the basic scenarios we run into during day-to-day development.
The repository contains an application that starts an HTTP server with three routes. Each route has one specific problem.
In this particular setup, those problems are:
CPU-intensive task, which blocks the main thread.
Asynchronous operation with a waterfall problem (the execution goes one by one instead of parallel).
Memory leak.
Each route has two implementations. One contains a problem that we should be able to spot with the DevTools, and the other is an optimized version with the same functionality.
Profiling
To start using DevTools with Node.js, we must run our server using the Node.js inspector.
node --inspect app.js
In short, the inspector provides the ability to interact with the V8 inspector.
After that, type chrome://inspect in your browser's search bar. You should see the following page:

Click the “Open dedicated DevTools for Node” button. You’ll see the DevTools connected to the node process you’re running.
To measure the performance of the connected Node.js app, you go to the “Performance” tab and click the “Record” button.

After that, you’ll see the dialog indicating profiling status. You can stop it at any time by clicking the “Stop” button.

Now, let’s see how it works with the prepared endpoints.
CPU-intensive endpoint
We start with the CPU-intensive endpoint. Here is what both implementations of the endpoint look like.
Solution with high CPU consumption.
function runCpuIntensiveTask(cb) {
function fibonacciRecursive(n) {
if (n <= 1) {
return n;
}
return fibonacciRecursive(n - 1) + fibonacciRecursive(n - 2);
}
fibonacciRecursive(45);
cb();
}
Solution with low CPU consumption.
function runSmartCpuIntensiveTask(cb) {
function fibonacciIterative(n) {
if (n <= 1) {
return n;
}
let prev = 0, curr = 1;
for (let i = 2; i <= n; i++) {
const next = prev + curr;
prev = curr;
curr = next;
}
return curr;
}
fibonacciIterative(45)
cb();
}
Both versions calculate the 45th Fibonacci number. The first implementation uses recursion, and the second one employs the iterative approach.
After running the CPU-intensive endpoint with the implementation that consumes a lot of CPU, you see the following picture.
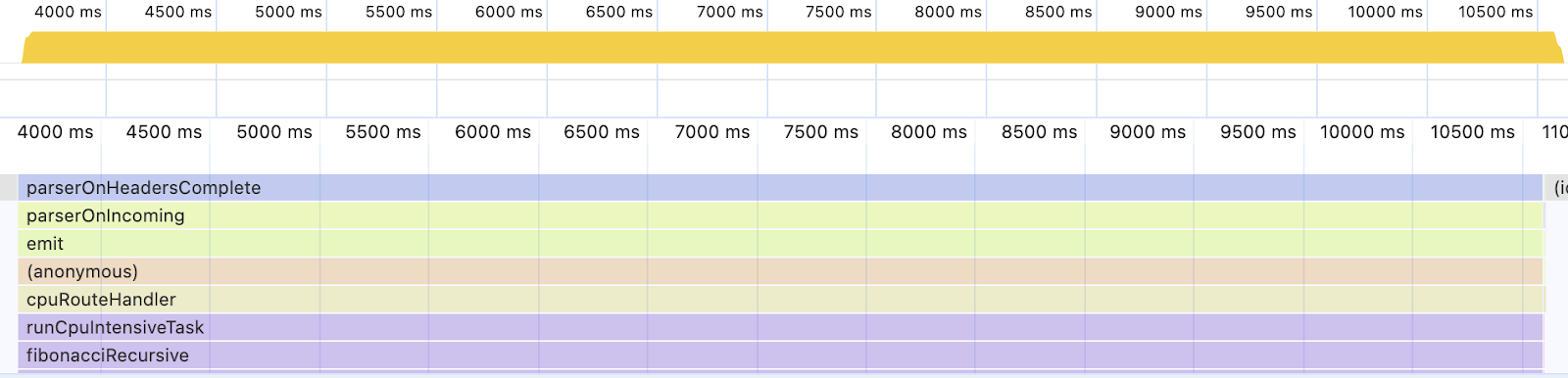
The breakdown of activities.

It is clear that the fibonacciRecursive function takes more than half of the execution time. This means that more than half of the time, the application exclusively works for the single function of a single request. This should be optimized.
The picture radically differs when we use the improved version with the same functionality.

It is barely noticeable. In the activity tab, we have the following picture.

The difference is enormous. We no longer block the main thread and consume way less CPU resources than before. It's definitely a win.
Async endpoint
Next on the list in the async endpoint. Here is what both implementations of the endpoint look like.
Solution with the waterfall effect.
function generateAsyncOperation() {
return new Promise(resolve => {
setTimeout(() => {
for (let i = 0; i < 50000000; i++) { }
resolve();
}, 1000);
});
}
async function runAsyncTask(cb) {
await generateAsyncOperation();
await generateAsyncOperation();
await generateAsyncOperation();
cb();
}
Solution with parallel execution.
function generateAsyncOperation() {
return new Promise(resolve => {
setTimeout(() => {
for (let i = 0; i < 50000000; i++) { }
resolve();
}, 1000);
});
}
export async function runSmartAsyncTask(cb) {
await Promise.all(
new Array(3).fill().map(() => generateAsyncOperation())
);
cb();
}
The result of the waterfall async function is that you see three spikes with intervals around 1000ms or one second. This means a function runs only after the previous one has finished running.

Since those are all async operations, we’re interested in a total execution time rather than non-blocking behavior. Each async request took around 1 second, and because of the waterfall effect, the function took 3 seconds to finish.
With the improved version, we have the following picture.

There was only one spike. Processing those three requests took the same time, but they are now running in parallel rather than one by one.
Memory leak endpoint
Here is what the code for both cases looks like.
Solution with a memory leak.
const memoryLeak = new Map();
export function runMemoryLeakTask(cb) {
for (let i = 0; i < 10000; i++) {
const person = {
name: `Person number ${i}`,
age: i,
};
memoryLeak.set(person, `I am a person number ${i}`);
}
cb();
}
Solution without a memory leak.
const smartMemoryLeak = new WeakMap();
export function runSmartMemoryLeakTask(cb) {
for (let i = 0; i < 10000; i++) {
const person = {
name: `Person number ${i}`,
age: i,
};
smartMemoryLeak.set(person, `I am a person number ${i}`);
}
cb();
}
All previous measurements were made using the performance tab inside DevTools. The memory tab also allows us to measure memory consumption.
You can find it right next to the performance tab.

There are three different approaches to this profiling.

We’ll choose the second option, “Allocation instrumentation on timeline.” That way, you’ll be able to see the memory consumption timeline, which is similar to the performance tab.
To start the profiling session, click the profile button at the top left corner.

First, we’ll send four requests to the memory leak endpoint with unoptimized implementation and record them using the profiler. You can clearly see four memory spikes on the timeline afterward.

The total size of the program is 11.5MB.
Below the timeline, you’ll see a table representing what is taking up the space.

While it is clear we have a lot of things going on here, like ~40,000 objects, it isn’t clear where they originate from. To find this connection, we’ll go back to the timeline and click the following selection.

You’ll see the “Allocation” option in the list. Choose it. Now you see the root of the problem.

It is the runMemoryLeakTask function that occupies most of the space. Let’s change it and run the optimized version instead with the same four requests. The result is impressive.

You can barely see requests except for the first one. The overall program size is reduced from 11.6 MB to 4.8 MB. It is ~2.5x less memory consumption.
Conclusion
The DevTools are amazing. They give you a wealth of information about CPU usage, detailed memory heap allocation, network communication, and much more.
While it provides everything you need in terms of information about everything that is going on inside the application, wouldn’t it be better if someone did the initial job of interpreting those results and giving you more human-readable instructions on what to do next?
That is what Clinic.js is all about. We’ll review it in the upcoming article.




